ai-workshop-2024
OceanBase AI 动手实战营
项目介绍
在这个动手实战营中,我们会构建一个 RAG 聊天机器人,用来回答与 OceanBase 文档相关的问题。它将采用开源的 OceanBase 文档仓库作为多模数据源,把文档转换为向量和结构化数据存储在 OceanBase 中。用户提问时,该机器人将用户的问题同样转换为向量之后在数据库中进行向量检索,结合向量检索得到的文档内容,借助通义千问提供的大语言模型能力来为用户提供更加准确的回答。
项目组成
该机器人将由以下几个组件组成:
- 将文档转换为向量的文本嵌入服务,在这里我们使用通义千问的嵌入 API
- 提供存储和查询文档向量和其他结构化数据能力的数据库,我们使用 OceanBase 4.3.3 版本
- 若干分析用户问题、基于检索到的文档和用户问题生成回答的 LLM 智能体,利用通义千问的大模型能力构建
- 机器人与用户交互的聊天界面,采用 Streamlit 搭建
交互流程
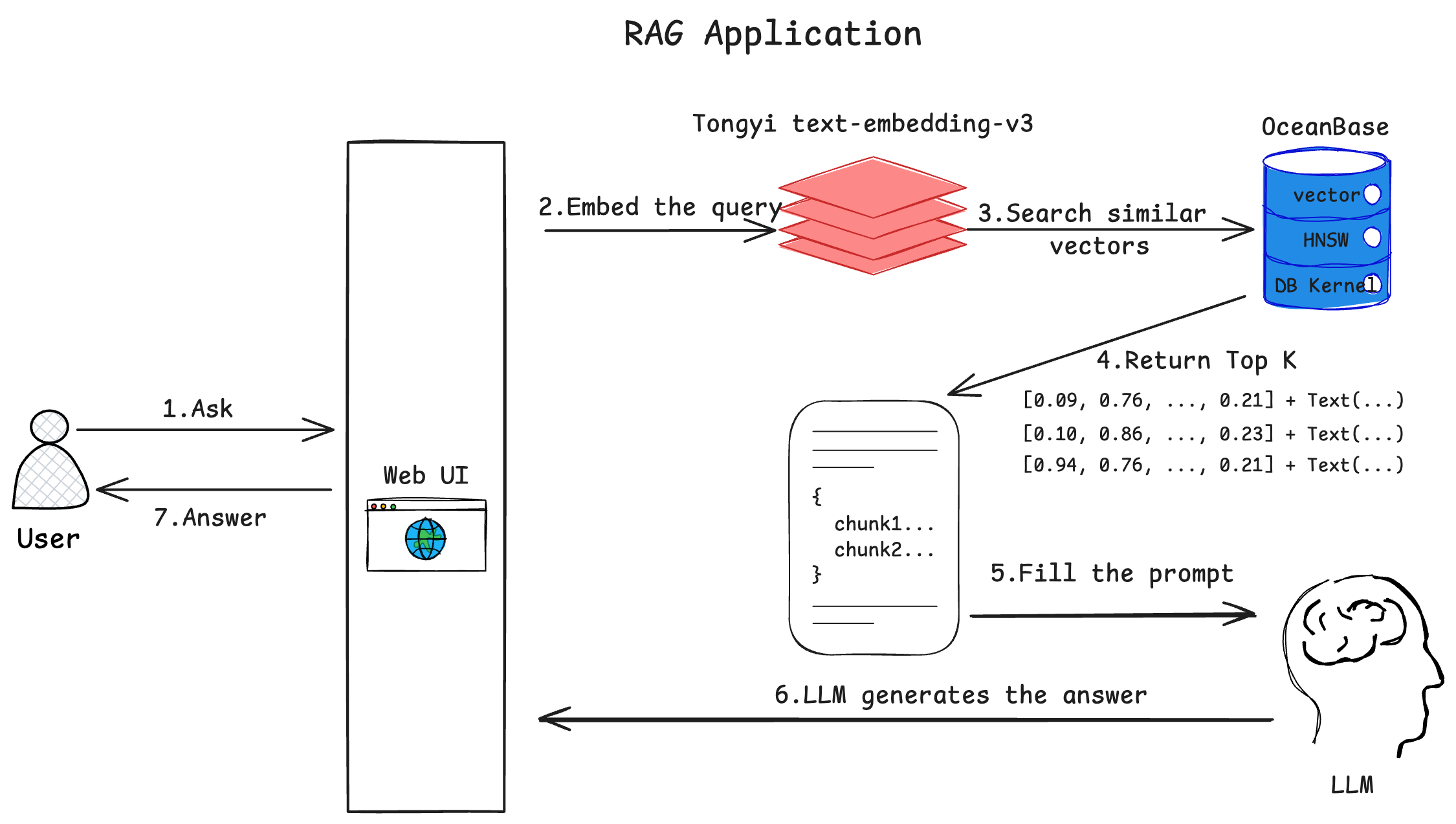
- 用户在 Web 界面中输入想要咨询的问题并发送给机器人
- 机器人将用户提出的问题使用文本嵌入模型转换为向量
- 将用户提问转换而来的向量作为输入在 OceanBase 中检索最相似的向量
- OceanBase 返回最相似的一些向量和对应的文档内容
- 机器人将用户的问题和查询到的文档一起发送给大语言模型并请它生成问题的回答
- 大语言模型分片地、流式地将答案返回给机器人
- 机器人将接收到的答案也分片地、流式地显示在 Web 界面中,完成一轮问答
概念解析
什么是文本嵌入?
文本嵌入是一种将文本转换为数值向量的技术。这些向量能够捕捉文本的语义信息,使计算机可以”理解”和处理文本的含义。具体来说:
- 文本嵌入将词语或句子映射到高维向量空间中的点
- 在这个向量空间中,语义相似的文本会被映射到相近的位置
- 向量通常由数百个数字组成(如 512 维、1024 维等)
- 可以用数学方法(如余弦相似度)计算向量之间的相似度
- 常见的文本嵌入模型包括 Word2Vec、BERT、BGE 等
在本项目中,我们使用通义千问的文本嵌入模型来生成文档的向量表示,这些向量将被存储在 OceanBase 数据库中用于后续的相似度检索。
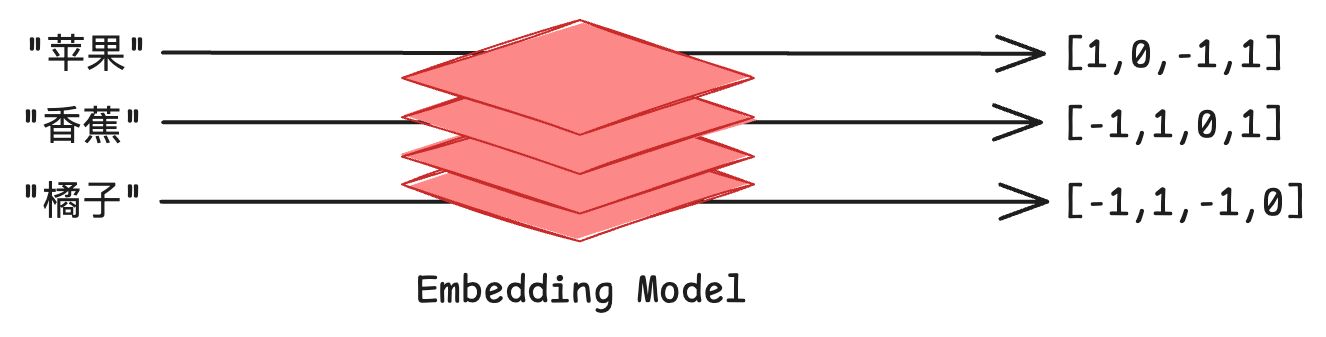
例如使用嵌入模型将“苹果”、“香蕉”和“橘子”分别转换为 4 维的向量,它们的向量表示可能如下图所示,需要注意的是我们为了方便表示,将向量的维度降低到了 4 维,实际上文本嵌入产生的向量维数通常是几百或者几千维,例如我们使用的通义千问 text-embedding-v3 产生的向量维度是 1024 维。
什么是向量检索?
向量检索是在向量数据库中快速找到与查询向量最相似的向量的技术。其核心特点包括:
- 基于向量间的距离(如欧氏距离)或相似度(如余弦相似度)进行搜索
- 通常使用近似最近邻(Approximate Nearest Neighbor, ANN)算法来提高检索效率
- OceanBase 4.3.3 支持 HNSW 算法,这是一种高效的 ANN 算法
- 使用 ANN 可以快速从百万甚至亿级别的向量中找到近似最相似的结果
- 相比传统关键词搜索,向量检索能更好地理解语义相似性
OceanBase 在关系型数据库模型基础上将“向量”作为一种数据类型进行了完好的支持,使得在 OceanBase 一款数据库中能够同时针对向量数据和常规的结构化数据进行高效的存储和检索。在本项目中,我们会使用 OceanBase 建立 HNSW (Hierarchical Navigable Small World) 向量索引来实现高效的向量检索,帮助我们快速找到与用户问题最相关的文档片段。
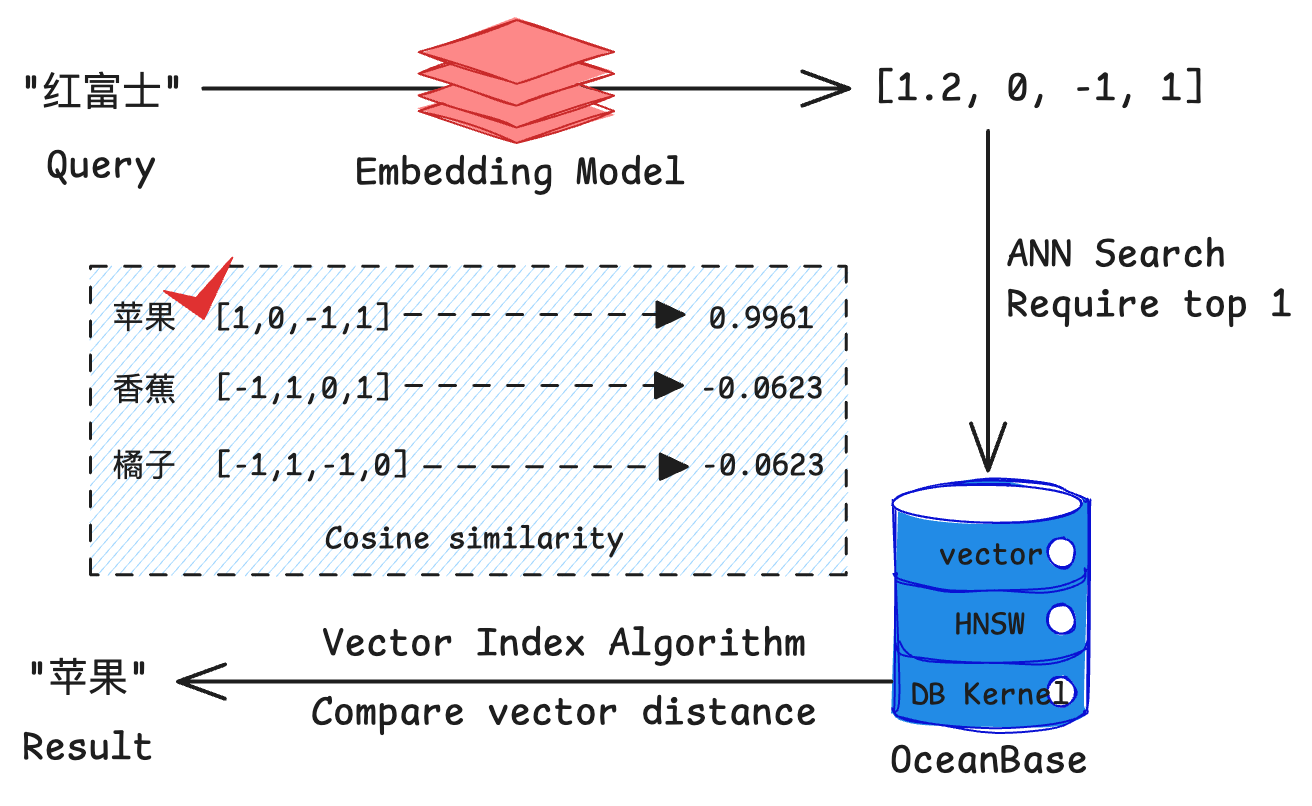
如果我们在已经嵌入“苹果”、“香蕉”和“橘子”的 OceanBase 数据库中使用“红富士”作为查询文本,那么我们可能会得到如下的结果,其中“苹果”和“红富士”之间的相似度最高。(假设我们使用余弦相似度作为相似度度量)
什么是 RAG?
RAG (Retrieval-Augmented Generation,检索增强生成) 是一种结合检索系统和生成式 AI 的混合架构,用于提高 AI 回答的准确性和可靠性。其工作流程为:
- 检索阶段:
- 将用户问题转换为向量
- 在知识库中检索相关文档
- 选择最相关的文档片段
- 生成阶段:
- 将检索到的文档作为上下文提供给大语言模型
- 大语言模型基于问题和上下文生成回答
- 确保回答的内容来源可追溯
RAG 的主要优势有:
- 降低大语言模型的幻觉问题
- 能够利用最新的知识和专业领域信息
- 提供可验证和可追溯的答案
- 适合构建特定领域的问答系统
大语言模型的训练和发布需要耗费较长的时间,且训练数据在开启训练之后便停止了更新。而现实世界的信息熵增无时无刻不在持续,要让大语言模型在“昏迷”几个月之后还能自发地掌握当下最新的信息显然是不现实的。而 RAG 就是让大模型用上了“搜索引擎”,在回答问题前先获取新的知识输入,这样通常能较大幅度地提高生成回答的准确性。
准备工作
注意:如果您正在参加 OceanBase AI 动手实战营,您可以跳过以下步骤 1 ~ 4。所有所需的软件都已经在机器上准备好了。:)
-
安装 Python 3.9+ 和 pip。如果您的机器上 Python 版本较低,可以使用 Miniconda 来创建新的 Python 3.9 及以上的环境,具体可参考 Miniconda 安装指南。
-
安装 Poetry,可参考命令
python3 -m pip install poetry -
安装 Docker(可选,如果您计划使用 Docker 在本地部署 OceanBase 数据库则必须安装)
-
安装 MySQL 客户端,可参考
yum install -y mysql或者apt-get install -y mysql-client(可选,如果您需要使用 MySQL 客户端检验数据库连接则必须安装) -
确保您机器上该项目的代码是最新的状态,建议进入项目目录执行
git pull -
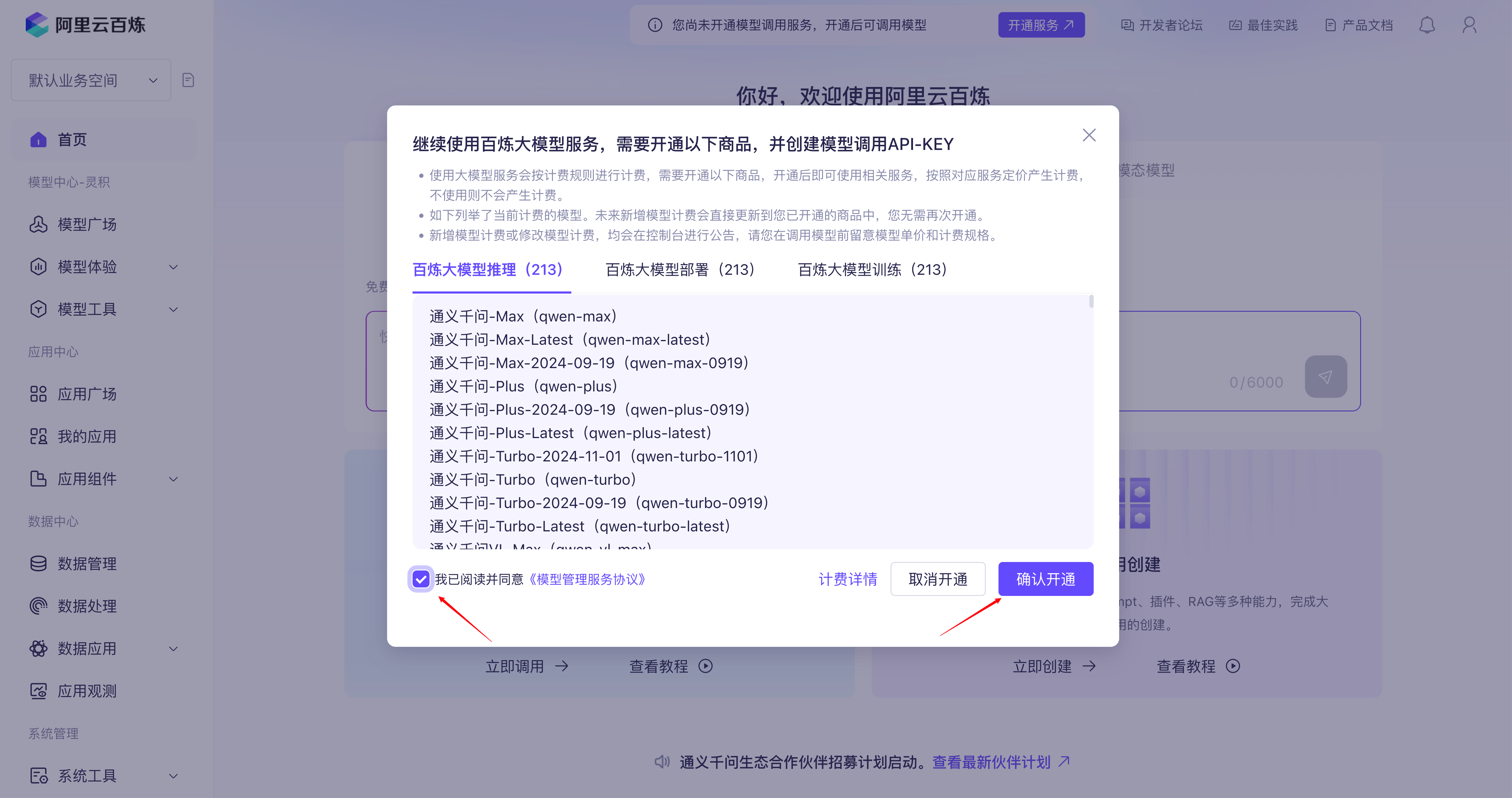
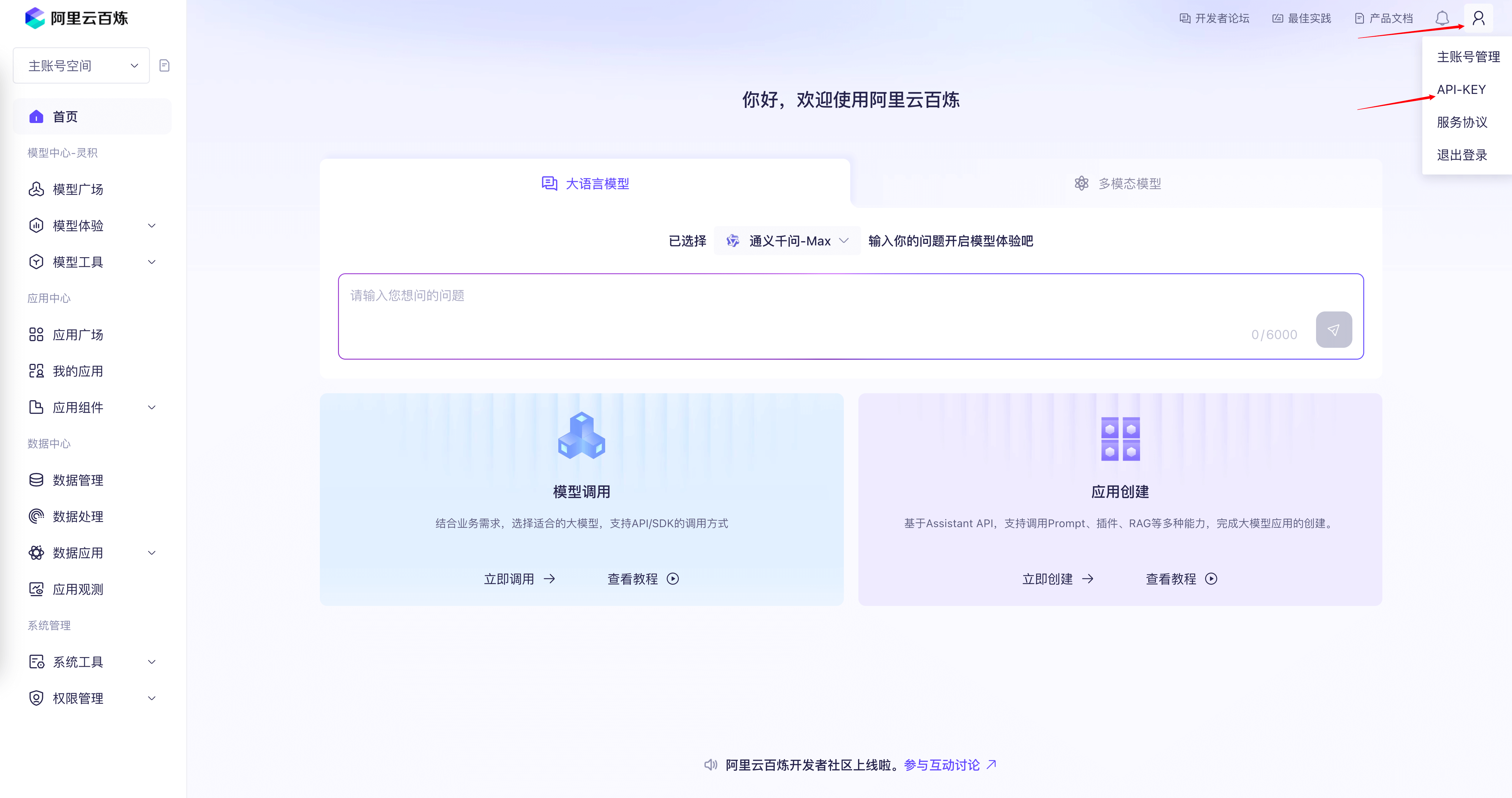
注册阿里云百炼账号,开通模型服务并获取 API Key

构建聊天机器人
1. 获取 OceanBase 数据库
我们首先要获取 OceanBase 4.3.3 版本及以上的数据库来存储我们的向量数据。您可以通过以下两种方式获取 OceanBase 数据库:
- 使用 OB Cloud 云数据库免费试用版,平台注册和实例开通请参考OB Cloud 云数据库 365 天免费试用;(推荐)
- 使用 Docker 启动单机版 OceanBase 数据库。(备选,需要有 Docker 环境,消耗较多本地资源)
1.1 使用 OB Cloud 云数据库免费试用版
注册并开通实例
进入OB Cloud 云数据库 365 天免费试用页面,点击“立即试用”按钮,注册并登录账号,填写相关信息,开通实例,等待创建完成。
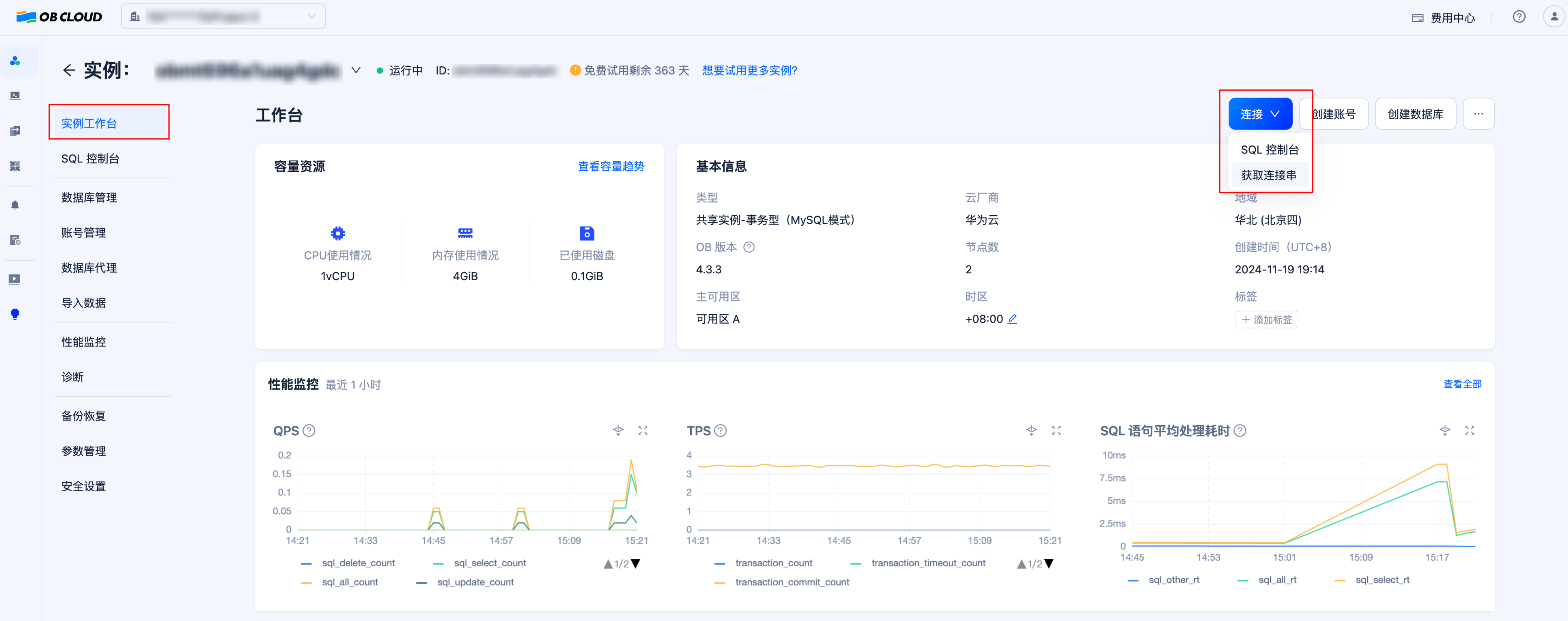
获取数据库实例连接串
进入实例详情页的“实例工作台”,点击“连接”-“获取连接串”按钮来获取数据库连接串,将其中的连接信息填入后续步骤中创建的 .env 文件内。
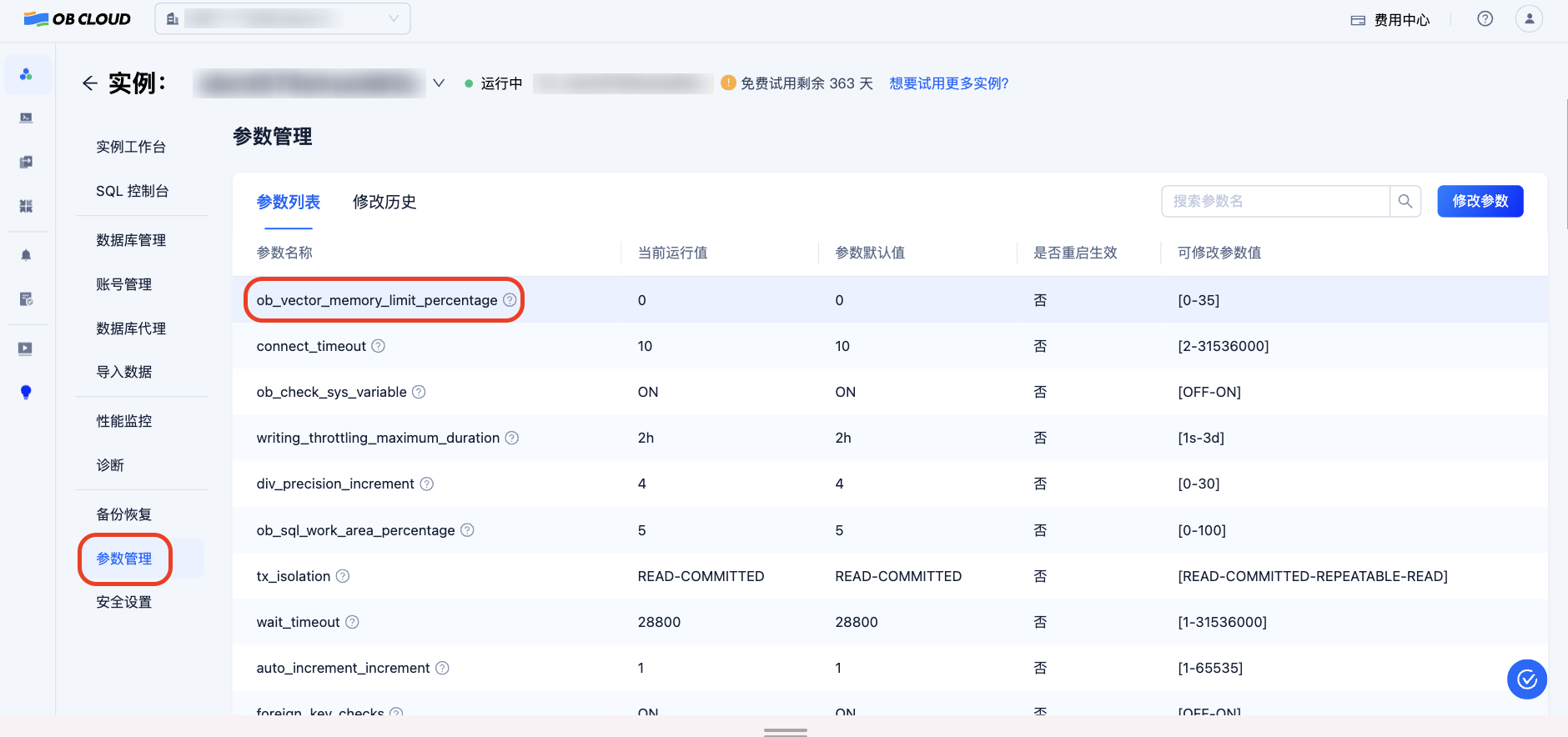
修改参数启用向量模块
进入实例详情页的“参数管理”,将 ob_vector_memory_limit_percentage 参数修改为 30 以启动向量模块。
1.2 使用 Docker 启动单机版 OceanBase 数据库
启动 OceanBase 容器
如果你是第一次登录动手实战营提供的机器,你需要通过以下命令启动 Docker 服务:
systemctl start docker
随后您可以使用以下命令启动一个 OceanBase docker 容器:
docker run --name=ob433 -e MODE=mini -e OB_MEMORY_LIMIT=8G -e OB_DATAFILE_SIZE=10G -e OB_CLUSTER_NAME=ailab2024 -e OB_SERVER_IP=127.0.0.1 -p 127.0.0.1:2881:2881 -d quay.io/oceanbase/oceanbase-ce:4.3.3.1-101000012024102216
如果上述命令执行成功,将会打印容器 ID,如下所示:
af5b32e79dc2a862b5574d05a18c1b240dc5923f04435a0e0ec41d70d91a20ee
检查 OceanBase 数据库初始化是否完成
容器启动后,您可以使用以下命令检查 OceanBase 数据库初始化状态:
docker logs -f ob433
初始化过程大约需要 2 ~ 3 分钟。当您看到以下消息(底部的 boot success! 是必须的)时,说明 OceanBase 数据库初始化完成:
cluster scenario: express_oltp
Start observer ok
observer program health check ok
Connect to observer ok
Initialize oceanbase-ce ok
Wait for observer init ok
+----------------------------------------------+
| oceanbase-ce |
+------------+---------+------+-------+--------+
| ip | version | port | zone | status |
+------------+---------+------+-------+--------+
| 172.17.0.2 | 4.3.3.1 | 2881 | zone1 | ACTIVE |
+------------+---------+------+-------+--------+
obclient -h172.17.0.2 -P2881 -uroot -Doceanbase -A
cluster unique id: c17ea619-5a3e-5656-be07-00022aa5b154-19298807cfb-00030304
obcluster running
...
check tenant connectable
tenant is connectable
boot success!
使用 Ctrl + C 退出日志查看界面。
测试数据库部署情况(可选)
可以使用 mysql 客户端连接到 OceanBase 集群,检查数据库部署情况。
mysql -h127.0.0.1 -P2881 -uroot@test -A -e "show databases"
如果部署成功,您将看到以下输出:
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| oceanbase |
| test |
+--------------------+
2. 安装依赖
接下来,您需要切换到动手实战营的项目目录:
cd ~/ai-workshop-2024
我们使用 Poetry 来管理聊天机器人项目的依赖项。您可以使用以下命令安装依赖项:
poetry install
如果您正在使用动手实战营提供的机器,您会看到以下消息,因为依赖都已经预先安装在了机器上:
Installing dependencies from lock file
No dependencies to install or update
3. 设置环境变量
我们准备了一个 .env.example 文件,其中包含了聊天机器人所需的环境变量。您可以将 .env.example 文件复制到 .env 并更新 .env 文件中的值。
cp .env.example .env
# 更新 .env 文件中的值,特别是 API_KEY 和数据库连接信息
vi .env
.env.example 文件的内容如下,如果您正在按照动手实战营的步骤进行操作(使用通义千问提供的 LLM 能力),您需要把 API_KEY 和 OPENAI_EMBEDDING_API_KEY 更新为您从阿里云百炼控制台获取的 API KEY 值,如果您使用 OB Cloud 的数据库实例,请将 DB_ 开头的变量更新为您的数据库连接信息,然后保存文件。
API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx # 填写 API Key
LLM_MODEL="qwen-turbo-2024-11-01"
LLM_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
HF_ENDPOINT=https://hf-mirror.com
BGE_MODEL_PATH=BAAI/bge-m3
OLLAMA_URL=
OLLAMA_TOKEN=
OPENAI_EMBEDDING_API_KEY= # 填写 API Key
OPENAI_EMBEDDING_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
OPENAI_EMBEDDING_MODEL=text-embedding-v3
UI_LANG="zh"
# 如果你使用的是 OB Cloud 的实例,请根据实例的连接信息更新下面的变量
DB_HOST="127.0.0.1"
DB_PORT="2881"
DB_USER="root@test"
DB_NAME="test"
DB_PASSWORD=""
4. 连接数据库
您可使用我们准备好的脚本来尝试连接数据库,以确保数据库相关的环境变量设置成功:
bash utils/connect_db.sh
# 如果顺利进入 MySQL 连接当中,则验证了环境变量设置成功
5. 准备文档数据
在该步骤中,我们将克隆 OceanBase 相关组件的开源文档仓库并处理它们,生成文档的向量数据和其他结构化数据后将数据插入到我们在步骤 1 中部署好的 OceanBase 数据库。
5.1 克隆文档仓库
首先我们将使用 git 克隆 oceanbase 的文档到本地。
git clone --single-branch --branch V4.3.4 https://github.com/oceanbase/oceanbase-doc.git doc_repos/oceanbase-doc
# 如果您访问 Github 仓库速度较慢,可以使用以下命令克隆 Gitee 的镜像版本
git clone --single-branch --branch V4.3.4 https://gitee.com/oceanbase-devhub/oceanbase-doc.git doc_repos/oceanbase-doc
5.2 文档格式标准化
因为 OceanBase 的开源文档中有些文件使用 ==== 和 ---- 来表示一级标题和二级标题,我们在这一步将其转化为标准的 # 和 ## 表示。
# 把文档的标题转换为标准的 markdown 格式
poetry run python convert_headings.py doc_repos/oceanbase-doc/zh-CN
5.3 将文档转换为向量并插入 OceanBase 数据库
我们提供了 embed_docs.py 脚本,通过指定文档目录和对应的组件后,该脚本就会遍历目录中的所有 markdown 格式的文档,将长文档进行切片后使用嵌入模型转换为向量,并最终将文档切片的内容、嵌入的向量和切片的元信息(JSON 格式,包含文档标题、相对路径、组件名称、切片标题、级联标题)一同插入到 OceanBase 的同一张表中,作为预备数据待查。
为了节省时间,我们只处理 OceanBase 众多文档中与向量检索有关的几篇文档,在第 6 步打开聊天界面之后,您针对 OceanBase 的向量检索功能进行的提问将得到较为准确的回答。
# 生成文档向量和元数据
poetry run python embed_docs.py --doc_base doc_repos/oceanbase-doc/zh-CN/640.ob-vector-search
在等待文本处理的过程中我们可以浏览 embed_docs.py 的内容,观察它是如何工作的。
首先在该文件中实例化了两个对象,一个是负责将文本内容转化为向量数据的嵌入服务 embeddings;另一个是 OceanBase 对接的 LangChain Vector Store 服务,封装了 pyobvector 这个 OceanBase 的向量检索 SDK,为用户提供简单易用的接口方法。同时我们针对 OceanBase 组件建立了分区键,在需要定向查询某个组件的文档时能极大提升效率。
embeddings = get_embedding(
ollama_url=os.getenv("OLLAMA_URL") or None,
ollama_token=os.getenv("OLLAMA_TOKEN") or None,
base_url=os.getenv("OPENAI_EMBEDDING_BASE_URL") or None,
api_key=os.getenv("OPENAI_EMBEDDING_API_KEY") or None,
model=os.getenv("OPENAI_EMBEDDING_MODEL") or None,
)
vs = OceanBase(
embedding_function=embeddings, # 传入嵌入服务,将在插入文档时即时调用
table_name=args.table_name,
connection_args=connection_args,
metadata_field="metadata",
extra_columns=[Column("component_code", Integer, primary_key=True)],
partitions=ObListPartition(
is_list_columns=False,
list_part_infos=[RangeListPartInfo(k, v) for k, v in cm.items()]
+ [RangeListPartInfo("p10", "DEFAULT")],
list_expr="component_code",
),
echo=args.echo,
)
接下来,该脚本判断所连接的 OceanBase 集群是否已开启了向量功能模块,如果没有开启则使用 SQL 命令进行启动。
# 通过查询 ob_vector_memory_limit_percentage 参数判断是否已开启向量功能模块
params = vs.obvector.perform_raw_text_sql(
"SHOW PARAMETERS LIKE '%ob_vector_memory_limit_percentage%'"
)
# ...
# 通过将 ob_vector_memory_limit_percentage 参数设置为 30 来开启向量功能模块
vs.obvector.perform_raw_text_sql(
"ALTER SYSTEM SET ob_vector_memory_limit_percentage = 30"
)
最后,我们遍历文档目录,将文档内容读取并切片之后提交给 OceanBase Vector Store 进行嵌入和存储。
if args.doc_base is not None:
loader = MarkdownDocumentsLoader(
doc_base=args.doc_base,
skip_patterns=args.skip_patterns,
)
batch = []
for doc in loader.load(limit=args.limit):
if len(batch) == args.batch_size:
insert_batch(batch, comp=args.component)
batch = []
batch.append(doc)
if len(batch) > 0:
insert_batch(batch, comp=args.component)
6. 启动聊天界面
执行以下命令启动聊天界面:
poetry run streamlit run --server.runOnSave false chat_ui.py
访问终端中显示的 URL 来打开聊天机器人应用界面。
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://172.xxx.xxx.xxx:8501
External URL: http://xxx.xxx.xxx.xxx:8501 # 这是您可以从浏览器访问的 URL
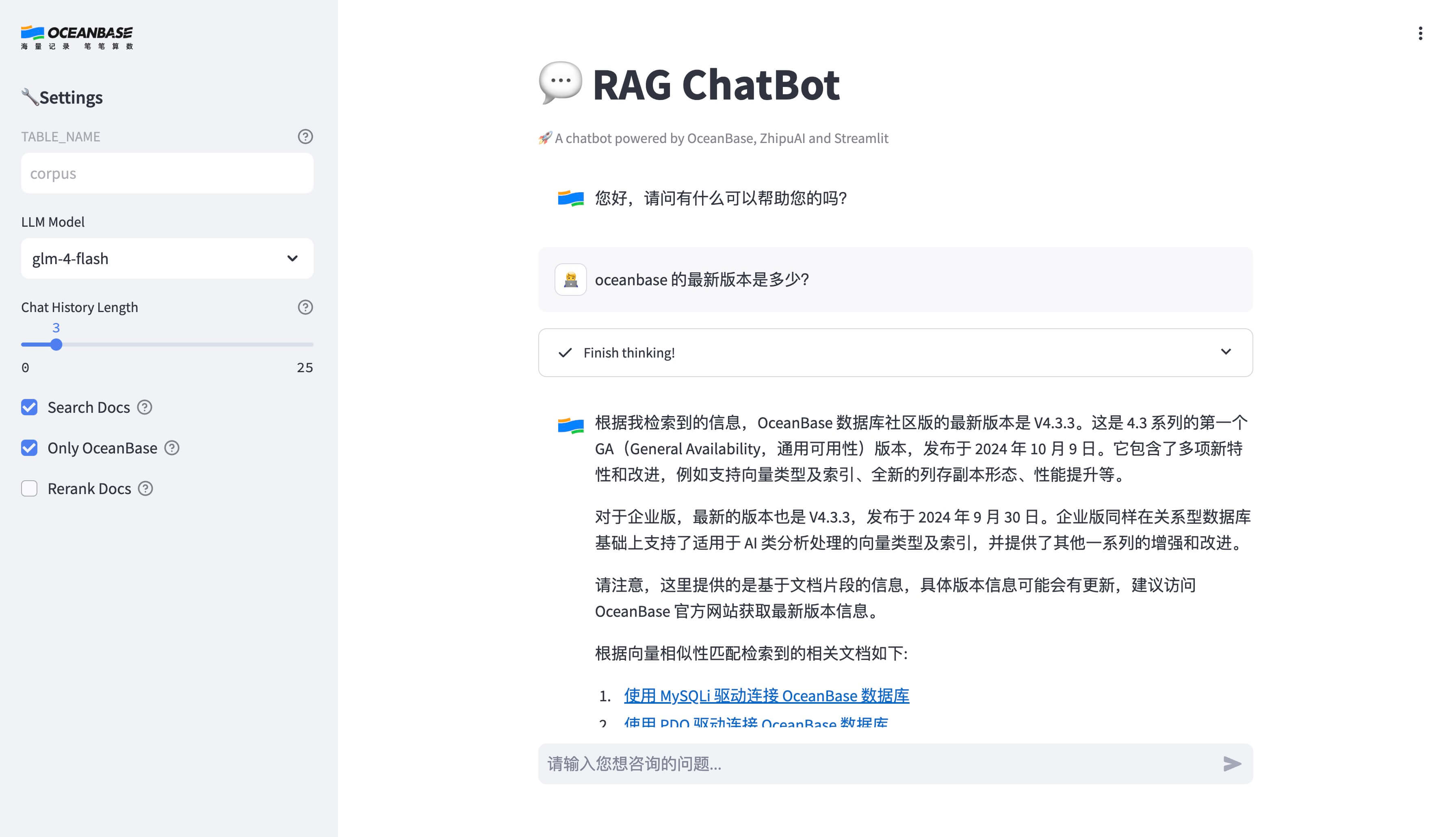
FAQ
1. 如何更改用于生成回答的 LLM 模型?
您可以通过更新 .env 文件中的 LLM_MODEL 环境变量来更改 LLM 模型,或者是在启动的对话界面左侧修改“大语言模型”。默认值是 qwen-turbo-2024-11-01,这是通义千问近期推出的具有较高免费额度的模型。还有其他可用的模型,如 qwen-plus、qwen-max、qwen-long 等。您可以在阿里云百炼网站的模型广场中找到完整的可用模型列表。请注意免费额度及计费标准。
2. 是否可以在初始加载后更新文档数据?
当然可以。您可以通过运行 embed_docs.py 脚本插入新的文档数据。例如:
# 这将在当前目录中嵌入所有 markdown 文件,其中包含 README.md 和 LEGAL.md
poetry run python embed_docs.py --doc_base .
# 或者您可以指定要插入数据的表
poetry run python embed_docs.py --doc_base . --table_name my_table
然后您可以在启动聊天界面之前指定 TABLE_NAME 环境变量,来指定聊天机器人将查询哪张表:
TABLE_NAME=my_table poetry run streamlit run --server.runOnSave false chat_ui.py
3. 如何查看嵌入和检索过程中数据库执行的操作?
当您自己插入文档时,可以设置 --echo 标志来查看脚本执行的 SQL 语句,如下所示:
poetry run python embed_docs.py --doc_base . --table_name my_table --echo
您将看到以下输出:
2024-10-16 03:17:13,439 INFO sqlalchemy.engine.Engine
CREATE TABLE my_table (
id VARCHAR(4096) NOT NULL,
embedding VECTOR(1024),
document LONGTEXT,
metadata JSON,
component_code INTEGER NOT NULL,
PRIMARY KEY (id, component_code)
)
...
您还可以在启动聊天界面之前设置 ECHO=true,以查看聊天界面执行的 SQL 语句。
ECHO=true TABLE_NAME=my_table poetry run streamlit run --server.runOnSave false chat_ui.py
4. 为什么我在启动 UI 服务后再编辑 .env 文件不再生效?
如果你编辑了 .env 文件或者是代码文件,需要重启 UI 服务才能生效。你可以通过 Ctrl + C 终止服务,然后重新运行 poetry run streamlit run --server.runOnSave false chat_ui.py 来重启服务。
5. 如何更改聊天界面的语言?
你可以通过更新 .env 文件中的 UI_LANG 环境变量来更改聊天界面的语言。默认值是 zh,表示中文。你可以将其更改为 en 来切换到英文。更新完成后需要重启服务才能生效。